import fastbook
fastbook.setup_book()Neural network image classifier using fast.ai and Pytorch modules
- Install required modules and get the training and validation data from MNIST.
::: {.cell _cell_guid=‘b1076dfc-b9ad-4769-8c92-a6c4dae69d19’ _uuid=‘8f2839f25d086af736a60e9eeb907d3b93b6e0e5’ execution=‘{“iopub.execute_input”:“2022-09-15T04:10:22.758163Z”,“iopub.status.busy”:“2022-09-15T04:10:22.757319Z”,“iopub.status.idle”:“2022-09-15T04:10:42.894549Z”,“shell.execute_reply”:“2022-09-15T04:10:42.893185Z”,“shell.execute_reply.started”:“2022-09-15T04:10:22.758077Z”}’ trusted=‘true’ execution_count=1}
pip install fastbook:::
from fastai.vision.all import *
from fastbook import *
matplotlib.rc('image', cmap='Greys')path = untar_data(URLs.MNIST_SAMPLE)
Path.BASE_PATH = path
100.14% [3219456/3214948 00:01<00:00]
# Check folder for labels
path.ls()(#3) [Path('valid'),Path('labels.csv'),Path('train')](path/'train').ls()(#2) [Path('train/7'),Path('train/3')]threes = (path/'train'/'3').ls().sorted()
sevens = (path/'train'/'7').ls().sorted()
threes(#6131) [Path('train/3/10.png'),Path('train/3/10000.png'),Path('train/3/10011.png'),Path('train/3/10031.png'),Path('train/3/10034.png'),Path('train/3/10042.png'),Path('train/3/10052.png'),Path('train/3/1007.png'),Path('train/3/10074.png'),Path('train/3/10091.png')...]im3_path = threes[1]
im3 = Image.open(im3_path)
im3
# Check the array of the digit '3'
array(im3)[4:10,4:10]array([[ 0, 0, 0, 0, 0, 0],
[ 0, 0, 0, 0, 0, 29],
[ 0, 0, 0, 48, 166, 224],
[ 0, 93, 244, 249, 253, 187],
[ 0, 107, 253, 253, 230, 48],
[ 0, 3, 20, 20, 15, 0]], dtype=uint8)#collapse_output
tensor(im3)[4:10,4:10]tensor([[ 0, 0, 0, 0, 0, 0],
[ 0, 0, 0, 0, 0, 29],
[ 0, 0, 0, 48, 166, 224],
[ 0, 93, 244, 249, 253, 187],
[ 0, 107, 253, 253, 230, 48],
[ 0, 3, 20, 20, 15, 0]], dtype=torch.uint8)# Use of pd dataframe to represent the the digit with a gradient
im3_t = tensor(im3)
df = pd.DataFrame(im3_t[:])
df.style.set_properties(**{'font-size':'6pt'}).background_gradient('Greys')| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 | 21 | 22 | 23 | 24 | 25 | 26 | 27 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 2 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 3 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 4 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 5 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 29 | 150 | 195 | 254 | 255 | 254 | 176 | 193 | 150 | 96 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 6 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 48 | 166 | 224 | 253 | 253 | 234 | 196 | 253 | 253 | 253 | 253 | 233 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 7 | 0 | 0 | 0 | 0 | 0 | 93 | 244 | 249 | 253 | 187 | 46 | 10 | 8 | 4 | 10 | 194 | 253 | 253 | 233 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 8 | 0 | 0 | 0 | 0 | 0 | 107 | 253 | 253 | 230 | 48 | 0 | 0 | 0 | 0 | 0 | 192 | 253 | 253 | 156 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 9 | 0 | 0 | 0 | 0 | 0 | 3 | 20 | 20 | 15 | 0 | 0 | 0 | 0 | 0 | 43 | 224 | 253 | 245 | 74 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 10 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 249 | 253 | 245 | 126 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 11 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 14 | 101 | 223 | 253 | 248 | 124 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 12 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 11 | 166 | 239 | 253 | 253 | 253 | 187 | 30 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 13 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 16 | 248 | 250 | 253 | 253 | 253 | 253 | 232 | 213 | 111 | 2 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 14 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 43 | 98 | 98 | 208 | 253 | 253 | 253 | 253 | 187 | 22 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 15 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 9 | 51 | 119 | 253 | 253 | 253 | 76 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 16 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 183 | 253 | 253 | 139 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 17 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 182 | 253 | 253 | 104 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 18 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 85 | 249 | 253 | 253 | 36 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 19 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 60 | 214 | 253 | 253 | 173 | 11 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 20 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 98 | 247 | 253 | 253 | 226 | 9 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 21 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 42 | 150 | 252 | 253 | 253 | 233 | 53 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 22 | 0 | 0 | 0 | 0 | 0 | 0 | 42 | 115 | 42 | 60 | 115 | 159 | 240 | 253 | 253 | 250 | 175 | 25 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 23 | 0 | 0 | 0 | 0 | 0 | 0 | 187 | 253 | 253 | 253 | 253 | 253 | 253 | 253 | 197 | 86 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 24 | 0 | 0 | 0 | 0 | 0 | 0 | 103 | 253 | 253 | 253 | 253 | 253 | 232 | 67 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 25 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 26 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 27 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
# Create a tesor containing all of the images in both training folders for both 7s and 3s
seven_tensors = [tensor(Image.open(o)) for o in sevens]
three_tensors = [tensor(Image.open(o)) for o in threes]
len(three_tensors),len(seven_tensors)(6131, 6265)#collapse_output
# Check one of the images created
show_image(three_tensors[1]);
# For every pixel position, compute the average over all of the images of the intensity of that pixel. Combine all of the images in this list into a single three-dimensional tensor (rank-3 tensor)
stacked_sevens = torch.stack(seven_tensors).float()/255
stacked_threes = torch.stack(three_tensors).float()/255
stacked_threes.shapetorch.Size([6131, 28, 28])# check the tensors rank
stacked_threes.ndim3# Given that or first dimension contains all of the images, we can compute the mean of all image tensors, i.e. compute the average of that pixel over all images.
mean3 = stacked_threes.mean(0)
show_image(mean3);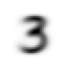
mean7 = stacked_sevens.mean(0)
show_image(mean7);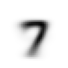
#collapse_output
# Check a random image and see how far its distance is from the ideal three
a_3 = stacked_threes[1]
show_image(a_3);
# Compute L1 norm (mean of the absolute value of dfferences) and L2 norm (RMSE)
dist_3_abs = (a_3 - mean3).abs().mean()
dist_3_sqr = ((a_3 - mean3)**2).mean().sqrt()
dist_3_abs,dist_3_sqr(tensor(0.1114), tensor(0.2021))dist_7_abs = (a_3 - mean7).abs().mean()
dist_7_sqr = ((a_3 - mean7)**2).mean().sqrt()
dist_7_abs,dist_7_sqr(tensor(0.1586), tensor(0.3021))# compute the same loss functions with Pytorch : torch.nn.functional (import as F)
F.l1_loss(a_3.float(),mean7), F.mse_loss(a_3,mean7).sqrt()(tensor(0.1586), tensor(0.3021))Compute Metrics using Broadcasting
Start by getting validation labels from the MNIST dataset for both digits
valid_3_tens = torch.stack([tensor(Image.open(o))
for o in (path/'valid'/'3').ls()])
valid_3_tens = valid_3_tens.float()/255
valid_7_tens = torch.stack([tensor(Image.open(o))
for o in (path/'valid'/'7').ls()])
valid_7_tens = valid_7_tens.float()/255
valid_3_tens.shape,valid_7_tens.shape(torch.Size([1010, 28, 28]), torch.Size([1028, 28, 28]))# Create a basic function that determines the distance between an image and our ideal 3 digit (Mean absolute error). The mean is computed on the horizontal and vertical axes i.e. -1 & -2
def mnist_distance(a,b):
return (a-b).abs().mean((-1,-2))
mnist_distance(a_3, mean3)tensor(0.1114)# calculate the distance for all of the 3s in the validation set compared to the valid_3_tens object - i.e. Pytorch will use broadcasting given that the tensors are of different rank
valid_3_dist = mnist_distance(valid_3_tens, mean3)
valid_3_dist, valid_3_dist.shape(tensor([0.1270, 0.1632, 0.1676, ..., 0.1228, 0.1210, 0.1287]),
torch.Size([1010]))# Create a function that to determine if the digit is a 3
def is_3(x): return mnist_distance(x,mean3) < mnist_distance(x,mean7)# Test it out
is_3(a_3), is_3(a_3).float()(tensor(True), tensor(1.))# Test our function on the whole validation set of 3s :
is_3(valid_3_tens)tensor([ True, False, False, ..., True, True, False])# Calculate the accuracy for each of the 3s and 7s by taking the average of that function for all 3s and its inverse for all 7s
accuracy_3s = is_3(valid_3_tens).float() .mean()
accuracy_7s = (1 - is_3(valid_7_tens).float()).mean()
accuracy_3s,accuracy_7s,(accuracy_3s+accuracy_7s)/2(tensor(0.9168), tensor(0.9854), tensor(0.9511))Use Stochastic Gradient Descent to optimize our prediction model
- Initialize the weights.
- For each image, use these weights to predict whether it appears to be a 3 or a 7.
- Based on these predictions, calculate how good the model is (its loss).
- Calculate the gradient, which measures for each weight, how changing that weight would change the loss
- Step (that is, change) all the weights based on that calculation.
- Go back to the step 2, and repeat the process.
- Iterate until we stop the training process
# Simple quadractic function that will be used for SGD
def f(x): return x**2# Get a tensor which will requre gradients
xt = tensor(3.).requires_grad_()yt = f(xt)
yttensor(9., grad_fn=<PowBackward0>)# Get Pytorch to calculate the gradients:
yt.backward()xt.gradtensor(6.)# Repeat the steps but with a vector argument
xt = tensor([3.,4.,10.]).requires_grad_()
xt
# Add sum to the quadratic function so it can take a vector (rank-1 tensor) and return a scalar (rank-0 tensor)
def f(x): return (x**2).sum()
yt = f(xt)
yttensor(125., grad_fn=<SumBackward0>)yt.backward()
xt.grad
lr = 1e-5tensor([ 6., 8., 20.])# Implement stepping with a learning rate
# w -= gradient(w) * lr# Loss function that will be used in our parameters, and quadratic function that will be used to measure the inputs vs the functions parameters
def mse(preds, targets): return ((preds-targets)**2).mean()
def f(t, params):
a,b,c = params
return a*(t**2) + (b*t) + cdef apply_step(params, prn=True):
preds = f(time, params)
loss = mse(preds, speed)
loss.backward()
params.data -= lr * params.grad.data
params.grad = None
if prn: print(loss.item())
return preds# Implementing th MNIST Loss function
# start by by concatenating all of our images (independant x variable) into a single tensor and change them from a list of matrices (rank-3 tensor) to a list of vectors (a rank-2 tensor) -- using Pytorch's
# view method.
train_x = torch.cat([stacked_threes, stacked_sevens]).view(-1, 28*28)# Create labels for each image
train_y = tensor([1]*len(threes) + [0]*len(sevens)).unsqueeze(1)
train_x.shape,train_y.shape(torch.Size([12396, 784]), torch.Size([12396, 1]))# zip together our dataset to crate a tuple
dset = list(zip(train_x,train_y))
x,y = dset[0]
x.shape,y(torch.Size([784]), tensor([1]))valid_x = torch.cat([valid_3_tens, valid_7_tens]).view(-1, 28*28)
valid_y = tensor([1]*len(valid_3_tens) + [0]*len(valid_7_tens)).unsqueeze(1)
valid_dset = list(zip(valid_x,valid_y))# Initialize random weights for every pixel
def init_params(size, std=1.0): return (torch.randn(size)*std).requires_grad_()weights = init_params((28*28,1))bias = init_params(1)# Calculate a prediction for one image
(train_x[0]*weights.T).sum() + biastensor([-6.2330], grad_fn=<AddBackward0>)def linear1(xb): return xb@weights + bias
preds = linear1(train_x)
predstensor([[ -6.2330],
[-10.6388],
[-20.8865],
...,
[-15.9176],
[ -1.6866],
[-11.3568]], grad_fn=<AddBackward0>)corrects = (preds>0.0).float() == train_y
correctstensor([[False],
[False],
[False],
...,
[ True],
[ True],
[ True]])corrects.float().mean().item()0.5379961133003235with torch.no_grad(): weights[0] *= 1.0001preds = linear1(train_x)
((preds>0.0).float() == train_y).float().mean().item()0.5379961133003235# implementing a loss function
def mnist_loss(predictions, targets):
predictions = predictions.sigmoid()
return torch.where(targets==1, 1-predictions, predictions).mean()# basic data set for our dataloader
ds = L(enumerate(string.ascii_lowercase))
ds(#26) [(0, 'a'),(1, 'b'),(2, 'c'),(3, 'd'),(4, 'e'),(5, 'f'),(6, 'g'),(7, 'h'),(8, 'i'),(9, 'j')...]# Putting the final model toogether
# Re-initialize parameters
weights = init_params((28*28,1))
bias = init_params(1)# create a DataLoader from a dataset
dl = DataLoader(dset, batch_size=256)
xb,yb = first(dl)
xb.shape,yb.shape(torch.Size([256, 784]), torch.Size([256, 1]))valid_dl = DataLoader(valid_dset, batch_size=256)# create a mini batch for testing
batch = train_x[:4]
batch.shapetorch.Size([4, 784])preds = linear1(batch)
predstensor([[14.0882],
[13.9915],
[16.0442],
[17.7304]], grad_fn=<AddBackward0>)loss = mnist_loss(preds, train_y[:4])
losstensor(4.1723e-07, grad_fn=<MeanBackward0>)# calculate the gradients
loss.backward()
weights.grad.shape,weights.grad.mean(),bias.grad(torch.Size([784, 1]), tensor(-5.9512e-08), tensor([-4.1723e-07]))# create a function to calculate the gradients
def calc_grad(xb, yb, model):
preds = model(xb)
loss = mnist_loss(preds, yb)
loss.backward()calc_grad(batch, train_y[:4], linear1)
weights.grad.mean(),bias.grad(tensor(-1.1902e-07), tensor([-8.3446e-07]))# call it again
calc_grad(batch, train_y[:4], linear1)
weights.grad.mean(),bias.grad(tensor(-1.7854e-07), tensor([-1.2517e-06]))# set the current gradients to 0 first (i.e. sets all the elements of the tensor bias to 0)
weights.grad.zero_()
bias.grad.zero_()# update the weights and biases on the gradient and learning rate
def train_epoch(model, lr, params):
for xb,yb in dl:
calc_grad(xb, yb, model)
for p in params:
p.data -= p.grad*lr
p.grad.zero_()# check predictions for a couple of images
(preds>0.0).float() == train_y[:4]tensor([[True],
[True],
[True],
[True]])# calculate our validation accuracy
def batch_accuracy(xb, yb):
preds = xb.sigmoid()
correct = (preds>0.5) == yb
return correct.float().mean()batch_accuracy(linear1(batch), train_y[:4])tensor(1.)# put the batches together
def validate_epoch(model):
accs = [batch_accuracy(model(xb), yb) for xb,yb in valid_dl]
return round(torch.stack(accs).mean().item(), 4)validate_epoch(linear1)0.5748# train again for an epoch and see if the accuracy improves
lr = 1.
params = weights,bias
train_epoch(linear1, lr, params)
validate_epoch(linear1)0.7251for i in range(20):
train_epoch(linear1, lr, params)
print(validate_epoch(linear1), end=' ')0.8569 0.9096 0.9296 0.9399 0.9467 0.9545 0.9569 0.9628 0.9647 0.9662 0.9672 0.9681 0.9725 0.9725 0.9725 0.973 0.9735 0.974 0.974 0.975 Creating an optimizer
- replace linear1 function with Pytorch’s nn.linear module reminder : nn.linear accomplishes the same thing as init_params and linear together - it contains both the weights and biases in a single class
linear_model = nn.Linear(28*28,1)# check out what parameters this module has that can be trained :
w,b = linear_model.parameters()
w.shape,b.shape(torch.Size([1, 784]), torch.Size([1]))# create the optimizer Class
class BasicOptim:
def __init__(self,params,lr): self.params,self.lr = list(params),lr
def step(self, *args, **kwargs):
for p in self.params: p.data -= p.grad.data * self.lr
def zero_grad(self, *args, **kwargs):
for p in self.params: p.grad = None# create the optimizer
opt = BasicOptim(linear_model.parameters(), lr)# the training loop can now be simplified to :
def train_epoch(model):
for xb,yb in dl:
calc_grad(xb, yb, model)
opt.step()
opt.zero_grad()# validation function is unchanged
validate_epoch(linear_model)0.6381# put the training loop into a function
def train_model(model, epochs):
for i in range(epochs):
train_epoch(model)
print(validate_epoch(model), end=' ')train_model(linear_model, 20)0.4932 0.7724 0.8559 0.916 0.935 0.9472 0.9579 0.9628 0.9658 0.9677 0.9697 0.9716 0.9741 0.975 0.976 0.9765 0.9775 0.978 0.978 0.978 # same results as previously
# fast ai SGD class is the same as our BasicOptim class, therefore:
linear_model = nn.Linear(28*28,1)
opt = SGD(linear_model.parameters(), lr)
train_model(linear_model, 20)0.4932 0.831 0.8398 0.9116 0.934 0.9477 0.956 0.9623 0.9658 0.9667 0.9697 0.9726 0.9741 0.975 0.9755 0.9765 0.9775 0.9785 0.9785 0.9785 # before creating the learner we need to create a dataloaders by passing it our training and validation:
dls = DataLoaders(dl, valid_dl)# to create a learner we will need to pass it all of our elements : a DataLoaders class, the model, optimization function (which will be passed the parameters), the loss function,
learn = Learner(dls, nn.Linear(28*28,1), opt_func=SGD,
loss_func=mnist_loss, metrics=batch_accuracy)learn.fit(10, lr=lr)| epoch | train_loss | valid_loss | batch_accuracy | time |
|---|---|---|---|---|
| 0 | 0.637040 | 0.503638 | 0.495584 | 00:00 |
| 1 | 0.596475 | 0.159199 | 0.878312 | 00:00 |
| 2 | 0.216541 | 0.197214 | 0.819431 | 00:00 |
| 3 | 0.093282 | 0.111199 | 0.908243 | 00:00 |
| 4 | 0.047910 | 0.080145 | 0.931305 | 00:00 |
| 5 | 0.030276 | 0.063814 | 0.946025 | 00:00 |
| 6 | 0.023095 | 0.053701 | 0.955348 | 00:00 |
| 7 | 0.019960 | 0.046993 | 0.961727 | 00:00 |
| 8 | 0.018413 | 0.042308 | 0.965162 | 00:00 |
| 9 | 0.017511 | 0.038881 | 0.967125 | 00:00 |
Adding Nonlinearity
# example of a simple neural network, incoporating ReLU
def simple_net(xb):
res = xb@w1 + b1
res = res.max(tensor(0.0))
res = res@w2 + b2
return resw1 = init_params((28*28,30))
b1 = init_params(30)
w2 = init_params((30,1))
b2 = init_params(1)# take advantage of Pytorch's library
simple_net = nn.Sequential(
nn.Linear(28*28,30),
nn.ReLU(),
nn.Linear(30,1)
)learn = Learner(dls, simple_net, opt_func=SGD,
loss_func=mnist_loss, metrics=batch_accuracy)learn.fit(40, 0.1)| epoch | train_loss | valid_loss | batch_accuracy | time |
|---|---|---|---|---|
| 0 | 0.385122 | 0.388649 | 0.520118 | 00:00 |
| 1 | 0.170687 | 0.256767 | 0.771835 | 00:00 |
| 2 | 0.090929 | 0.123868 | 0.908734 | 00:00 |
| 3 | 0.057405 | 0.081251 | 0.938665 | 00:00 |
| 4 | 0.042229 | 0.062670 | 0.952895 | 00:00 |
| 5 | 0.034708 | 0.052418 | 0.963690 | 00:00 |
| 6 | 0.030526 | 0.046020 | 0.965653 | 00:00 |
| 7 | 0.027888 | 0.041687 | 0.966634 | 00:00 |
| 8 | 0.026028 | 0.038563 | 0.968106 | 00:00 |
| 9 | 0.024608 | 0.036192 | 0.968597 | 00:00 |
| 10 | 0.023467 | 0.034323 | 0.971050 | 00:00 |
| 11 | 0.022520 | 0.032800 | 0.973013 | 00:00 |
| 12 | 0.021717 | 0.031524 | 0.973503 | 00:00 |
| 13 | 0.021023 | 0.030433 | 0.974975 | 00:00 |
| 14 | 0.020417 | 0.029485 | 0.974975 | 00:00 |
| 15 | 0.019881 | 0.028649 | 0.975466 | 00:00 |
| 16 | 0.019402 | 0.027905 | 0.975957 | 00:00 |
| 17 | 0.018971 | 0.027236 | 0.976938 | 00:00 |
| 18 | 0.018580 | 0.026633 | 0.977429 | 00:00 |
| 19 | 0.018223 | 0.026085 | 0.978410 | 00:00 |
| 20 | 0.017895 | 0.025584 | 0.978410 | 00:00 |
| 21 | 0.017592 | 0.025126 | 0.978901 | 00:00 |
| 22 | 0.017310 | 0.024705 | 0.978901 | 00:00 |
| 23 | 0.017048 | 0.024316 | 0.979882 | 00:00 |
| 24 | 0.016803 | 0.023957 | 0.980373 | 00:00 |
| 25 | 0.016572 | 0.023623 | 0.980373 | 00:00 |
| 26 | 0.016355 | 0.023313 | 0.980864 | 00:00 |
| 27 | 0.016150 | 0.023025 | 0.980864 | 00:00 |
| 28 | 0.015955 | 0.022756 | 0.981354 | 00:00 |
| 29 | 0.015771 | 0.022505 | 0.981354 | 00:00 |
| 30 | 0.015595 | 0.022270 | 0.981354 | 00:00 |
| 31 | 0.015427 | 0.022051 | 0.981845 | 00:00 |
| 32 | 0.015267 | 0.021844 | 0.981845 | 00:00 |
| 33 | 0.015114 | 0.021651 | 0.982826 | 00:00 |
| 34 | 0.014967 | 0.021469 | 0.982826 | 00:00 |
| 35 | 0.014827 | 0.021297 | 0.982826 | 00:00 |
| 36 | 0.014692 | 0.021135 | 0.982826 | 00:00 |
| 37 | 0.014562 | 0.020982 | 0.982826 | 00:00 |
| 38 | 0.014436 | 0.020837 | 0.982826 | 00:00 |
| 39 | 0.014315 | 0.020700 | 0.982826 | 00:00 |
# plot the accuracy over training :
plt.plot(L(learn.recorder.values).itemgot(2));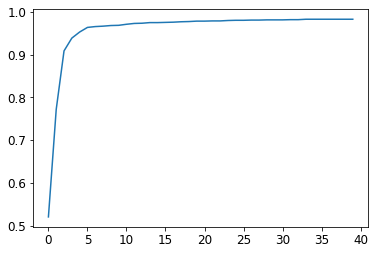
# final accuracy
learn.recorder.values[-1][2]0.982826292514801# train a 18-layer model using the same approach
dls = ImageDataLoaders.from_folder(path)
learn = vision_learner(dls, resnet18, pretrained=False,
loss_func=F.cross_entropy, metrics=accuracy)
learn.fit_one_cycle(1, 0.1)| epoch | train_loss | valid_loss | accuracy | time |
|---|---|---|---|---|
| 0 | 0.074170 | 0.031738 | 0.994112 | 00:23 |